from :https://www.oceanbase.com/docs/community-tutorials-cn-1000000001390068
执行计划(Execution Plan)是对一条 SQL 查询语句在数据库中执行过程的描述。
用户可以通过 EXPLAIN 命令查看优化器针对指定 SQL 生成的执行计划。如果要分析某条 SQL 的性能问题,通常需要先查看 SQL 的执行计划,排查每一步 SQL 执行是否存在问题。所以读懂执行计划是 SQL 优化的先决条件,而了解执行计划的算子是理解 EXPLAIN 命令的关键。
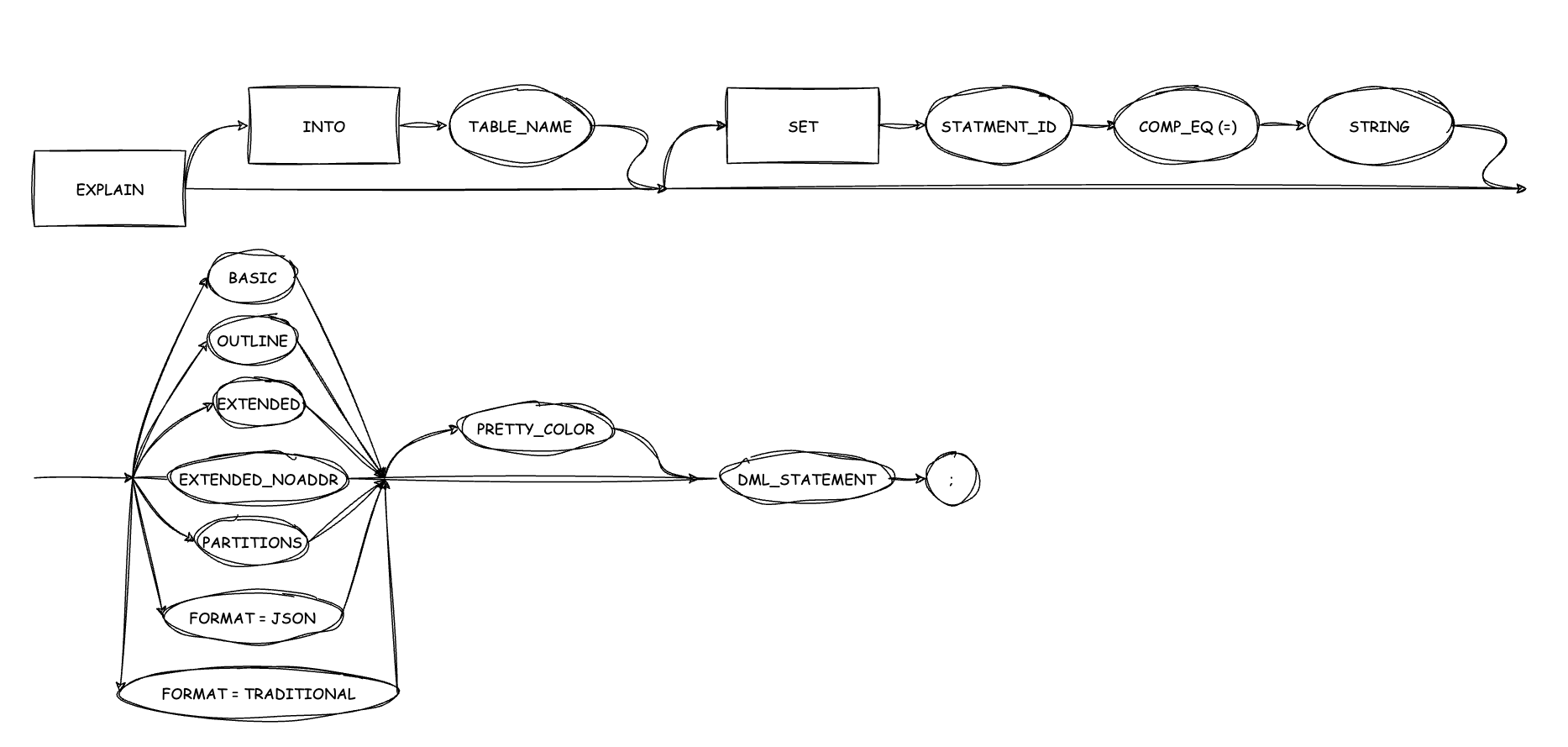
EXPLAIN 命令格式
该语句用于解释 SQL 语句的执行计划,可以是 SELECT、DELETE、INSERT、REPLACE 或 UPDATE 语句。
EXPLAIN 与 DESCRIBE、DESC 互为同义词。
语法
{EXPLAIN [INTO table_name ] [SET statement_id = string]}
[explain_type] [PRETTY | PRETTY_COLOR] dml_statement;
explain_type:
BASIC
| OUTLINE
| EXTENDED
| EXTENDED_NOADDR
| PARTITIONS
| FORMAT = {TRADITIONAL| JSON}
dml_statement:
SELECT statement
| DELETE statement
| INSERT statement
| REPLACE statement参数解释
参数 描述 INTO table_name 表示将 EXPLAIN 的计划信息保存到指定表内。如果没有指定 INTO table_name,默认查询到 PLAN_TABLE 表内。 SET statement_id 表示当前查询使用字符串标记,以方便后续查询该 SQL 的计划信息。如果没有指定 SET statement_id,默认使用空字符串作为信息标记。 PRETTY | PRETTY_COLOR 将计划树中的父节点和子节点使用树线或彩色树线连接起来,使得执行计划展示更方便阅读。 BASIC 指定输出计划的基础信息,如算子 ID、算子名称、所引用的表名。 OUTLINE 指定输出的计划信息包含 OUTLINE 信息。 EXTENDED 展示附加信息。 EXTENDED_NOADDR 以简约的方式展示附加信息。 PARTITIONS 显示分区相关信息。 FORMAT = {TRADITIONAL| JSON} 指定 EXPALIN 的输出格式。TRADITIONAL:表格输出格式;JSON:KEY:VALUE 输出格式,JSON 显示为 JSON 字符串,包括 EXTENDED 和 PARTITIONS 信息。 dml_statement DML 语句。
对于 OceanBase 数据库的使用者来说,最常用的是 EXPLAIN 命令和 EXPLAIN EXTENDED_NOADDR 命令。
EXPLAIN 所展示的信息可以快速帮助普通用户了解整个计划的执行方式。例如:
create table t1(c1 int, c2 int);
create table t2(c1 int, c2 int);
-- 向 t1 表插入 10 行测试数据,c1 列的值是从 1 到 1000 的连续整数。
insert into t1 with recursive cte(n) as (select 1 from dual union all select n + 1 from cte where n < 1000) select n, n from cte;
-- 向 t2 表插入 10 行测试数据,c1 列的值是从 1 到 1000 的连续整数。
insert into t2 with recursive cte(n) as (select 1 from dual union all select n + 1 from cte where n < 1000) select n, n from cte;
-- 收集指定表 t1 的统计信息
analyze table t1 COMPUTE STATISTICS for all columns size 128;
-- 收集指定表 t2 的统计信息
analyze table t2 COMPUTE STATISTICS for all columns size 128;
explain select * from t1, t2 where t1.c1 = t2.c1 and t1.c1 < 500;
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| ================================================= |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------- |
| |0 |HASH JOIN | |498 |315 | |
| |1 |├─TABLE FULL SCAN|t1 |499 |76 | |
| |2 |└─TABLE FULL SCAN|t2 |499 |76 | |
| ================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2], [t2.c1], [t2.c2]), filter(nil), rowset=256 |
| equal_conds([t1.c1 = t2.c1]), other_conds(nil) |
| 1 - output([t1.c1], [t1.c2]), filter([t1.c1 < 500]), rowset=256 |
| access([t1.c1], [t1.c2]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.__pk_increment]), range(MIN ; MAX)always true |
| 2 - output([t2.c1], [t2.c2]), filter([t2.c1 < 500]), rowset=256 |
| access([t2.c1], [t2.c2]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t2.__pk_increment]), range(MIN ; MAX)always true |
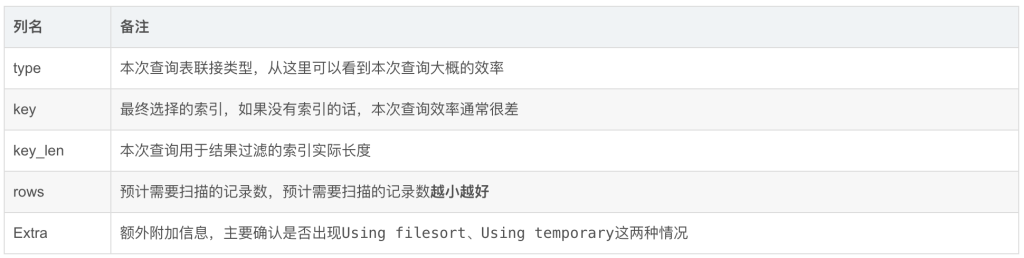
+------------------------------------------------------------------------------------+OceanBase 数据库执行计划中的各列的含义如下表所示。
列名 含义 ID 执行树按照前序遍历的方式得到的编号(从 0 开始)。 OPERATOR 操作算子的名称。 NAME 对应表操作的表名(索引名)。 EST. ROWS 优化器估算该操作算子的输出行数,仅作为参考。TABLE FULL SCAN,因为过滤条件有 t1.c1 < 500,所以优化器根据这 1000 行数据的统计信息,可以估算出过滤之后需要输出的数据行数为 499 行。 EST.TIME 优化器估算该操作算子的执行代价(微秒),仅作为参考。
在表操作中,NAME 字段会显示该操作涉及的表的名称(别名),如果是使用索引访问,还会在名称后的括号中展示该索引的名称,例如 t1(t1_c2) 表示使用了索引 t1_c2。如果扫描的顺序是逆序,还会在后面使用 RESERVE 关键字标识,例如 t1(t1_c2,RESERVE)。
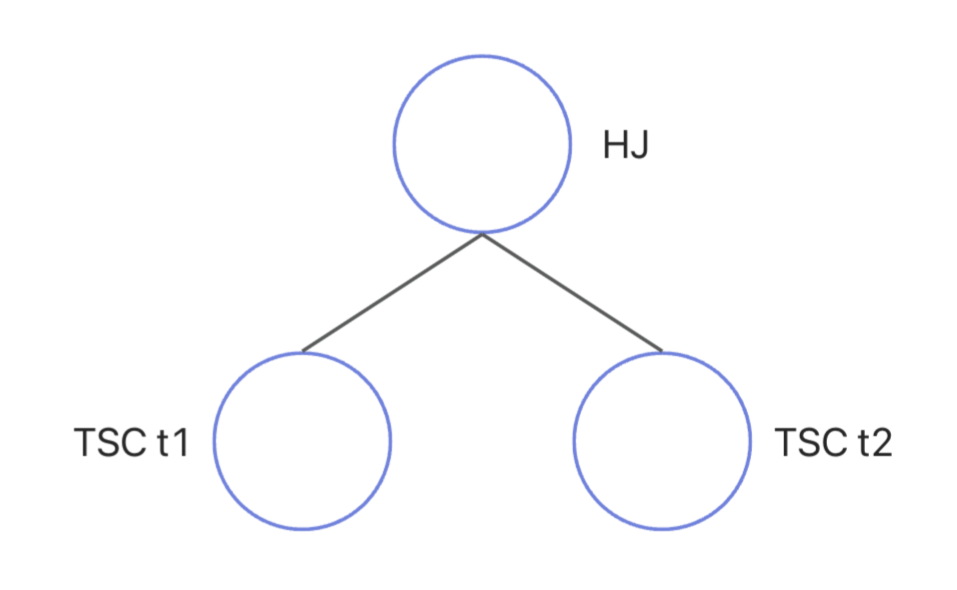
OceanBase 数据库 EXPLAIN 命令输出的第一部分是执行计划的树形结构展示。其中每一个操作在树中的层次通过其在算子中的缩进予以展示。树的层次关系用缩进来表示,层次最深的优先执行,层次相同的算子以指定算子的执行顺序为标准来执行。上述示例查询的计划展示树如下图所示:
其中,0 号算子是一个 hash join(HJ) 算子,它有两个子节点,分别是 1 和 2 号 table scan 算子(TSC)。0 号 hash join 算子的执行逻辑如下:
读取左子节点的数据,根据联接列计算哈希值,构建一张哈希表。
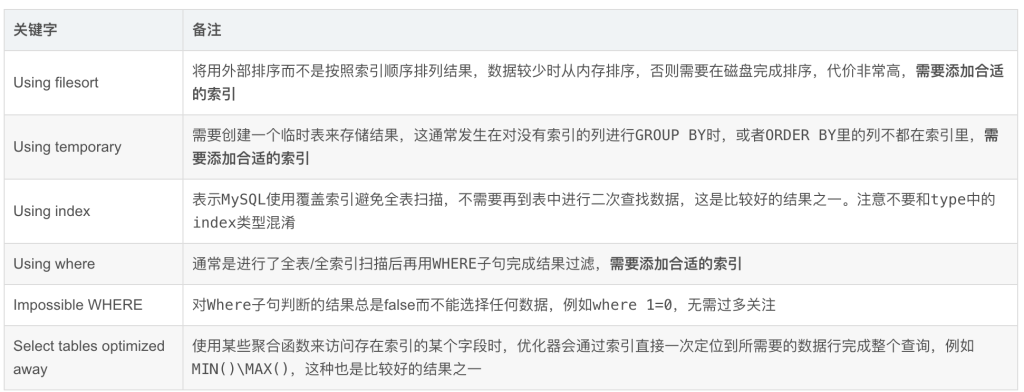
读取右子节点的数据,根据联接列计算哈希值,尝试使用通过左支数据构建的哈希表进行哈希探测,完成联接计算。 OceanBase 数据库 EXPLAIN 命令输出的第二部分是各操作算子的详细信息,包括输出表达式、过滤条件、分区信息以及各算子的独有信息(包括排序键、联接键、下压条件等)。即上述计划中的下半部分:
Outputs & filters:
-------------------------------------
0 - output([t1.c1], [t1.c2], [t2.c1], [t2.c2]), filter(nil), rowset=16
equal_conds([t1.c1 = t2.c1]), other_conds(nil)
1 - output([t1.c1], [t1.c2]), filter([t1.c1 > 10]), rowset=16
access([t1.c1], [t1.c2]), partitions(p0)
is_index_back=false, is_global_index=false, filter_before_indexback[false],
range_key([t1.__pk_increment]), range(MIN ; MAX)always true
2 - output([t2.c1], [t2.c2]), filter([t2.c1 > 10]), rowset=16
access([t2.c1], [t2.c2]), partitions(p0)
is_index_back=false, is_global_index=false, filter_before_indexback[false],
range_key([t2.__pk_increment]), range(MIN ; MAX)always true第二部分的内容跟第一部分有关,主要是描述第一部分算子的具体信息。其中一些公共的信息如下。
output : 该算子的输出表达式。
filter : 该算子的过滤谓词。 如果算子没有设置过滤条件,则为 nil。 为了更好地读懂 OceanBase 数据库 EXPLAIN 计划中各个算子的第二部分,需要用户对各个算子的作用有一个初步的了解,具体介绍可参见官网《OceanBase 数据库》文档 参考指南/性能调优/SQL 调优指南/SQL 执行计划/执行计划算子 章节。 例如上面这个计划,用户需要通过官网《OceanBase 数据库》文档中 参考指南/性能调优/SQL 调优指南/SQL 执行计划/执行计划算子/TABLE SCAN 内容和 参考指南/性能调优/SQL 调优指南/SQL 执行计划/执行计划算子/JOIN 一文中的 HASH JOIN 内容的介绍来读懂上面这部分内容,大家不妨一试。
说明
上述计划中的 rowset=16 和 OceanBase 数据库执行引擎的向量化执行技术相关。表示在特定算子中,会按照 16 行一组分批进行计算。
用户可以通过 _rowsets_enabled 对向量化开关进行打开或关闭,例如通过 alter system set _rowsets_enabled = 0; 关闭向量化开关。用户也可以通过 _rowsets_max_rows 对向量化执行中一批处理的行数进行设置,例如通过 alter system set_rowsets_max_rows = 4; 将向量化执行中一批数据的行数改为 4。
向量化更详细的内容不在这里展开,感兴趣的用户可以阅读 OceanBase 社区博客《OceanBase 轻量级数仓关键技术解读》 中的 向量化执行技术 部分。
EXPLAIN EXTENDED_NOADDR 命令用于进行详细的计划展示。通常用户在排查 SQL 性能问题时,会使用这种展示模式。
CREATE TABLE `t1` (
`c1` int, `c2` int,
KEY `idx` (`c1`));
insert into t1 values(1, 2);
explain EXTENDED_NOADDR select * from t1 where c1 > 10;
+--------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------+
| =================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| --------------------------------------------------- |
| |0 |TABLE RANGE SCAN|t1(idx)|1 |7 | |
| =================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2]), filter(nil), rowset=16 |
| access([t1.__pk_increment], [t1.c1], [t1.c2]), partitions(p0) |
| is_index_back=true, is_global_index=false, |
| range_key([t1.c1], [t1.__pk_increment]), range(10,MAX ; MAX,MAX), |
| range_cond([t1.c1 > 10]) |
| Used Hint: |
| ------------------------------------- |
| /*+ |
| |
| */ |
| Qb name trace: |
| ------------------------------------- |
| stmt_id:0, stmt_type:T_EXPLAIN |
| stmt_id:1, SEL$1 |
| Outline Data: |
| ------------------------------------- |
| /*+ |
| BEGIN_OUTLINE_DATA |
| INDEX(@"SEL$1" "test"."t1"@"SEL$1" "idx") |
| OPTIMIZER_FEATURES_ENABLE('4.0.0.0') |
| END_OUTLINE_DATA |
| */ |
| Optimization Info: |
| ------------------------------------- |
| t1: |
| table_rows:1 |
| physical_range_rows:1 |
| logical_range_rows:1 |
| index_back_rows:1 |
| output_rows:1 |
| table_dop:1 |
| dop_method:Table DOP |
| avaiable_index_name:[idx, t1] |
| unstable_index_name:[t1] |
| stats version:0 |
| dynamic sampling level:0 |
| Plan Type: |
| LOCAL |
| Note: |
| Degree of Parallelisim is 1 because of table property |
+--------------------------------------------------------------------------+
47 rows in set上图中的 Optimization Info 往往可以用于分析一些 SQL 的性能问题,其中重要信息的介绍如下。
Optimization Info 含义解释 table_rows 上一个合并版本 SSTable 中的表的行数,可以简单理解为 t1 表的行数,只具有参考意义。 physical_range_rows t1 表需要扫描的物理行数。如果走了索引的话,含义为 t1 表在索引上需要扫描的物理行数。logical_range_rows t1 表在需要扫描的逻辑行数。如果走了索引的话,含义为 t1 表在索引上需要扫描的逻辑行数。在上面这个计划中,因为扫描了 idx 索引,所以能看到扫描范围都是 range(10,MAX ; MAX,MAX),range_cond([t1.c1 > 10])。如果没有索引,则需要扫描全表,这时扫描的范围会变为 range(MIN ; MAX)。注意 physical_range_rows 和 logical_range_rows 这两个指标一般来说是相近的,看任意一个都可以。仅在一些特殊的 Buffer 表场景下,physical_range_rows 可能会远大于 logical_range_rows。Buffer 表表示频繁插入、删除的表。当 LSM tree 中的增量数据中积累了大量标记删除的数据时,从上层应用视角实际存在的行很少,但范围查询时可能需要处理较多的标记删除的数据,这种场景下,physical_range_rows 可能会远大于 logical_range_rows,从而导致 SQL 耗时不够理想。同时 Buffer 表场景下也容易导致优化器生成非最优执行计划。Buffer 表的介绍、检测逻辑,以及规避方法详见官网《OceanBase 数据库》文档 管理数据库/性能调优/识别组件内的瓶颈/OBServer 端性能瓶颈/非最优计划/Buffer 表 。index_back_rows 如果索引需要回表,这个值表示索引回表的行数。当全表扫描或者索引扫描但不需要回表时,该值为 0。索引回表的概念详见官网《OceanBase 数据库》文档 参考指南/性能调优/SQL 调优指南/SQL 执行计划/执行计划算子/TABLE SCAN 。简单来说,这个计划中索引需要回主表的原因是索引 idx 中只有 c1 列的数据,需要根据索引中过滤出来的数据对应到主表中的隐藏主键信息,回到主表中查出 c2 列的数据。如果这个查询不是 select * from t1 where c1 > 10,而是 select c1 from t1 where c1 > 10,因为索引中已经包含了需要查询的全部信息,则不需要索引回表。 output_rows 预估输出行数。在上面的计划中,表示 t1 表经过过滤之后的行数。 table_dop t1 表扫描时的并行度(并行执行时所使用的工作线程数)。dop_method 决定表扫描并行度的原因。可以是 TableDOP(表在定义时指定的并行度)、AutoDop(优化器基于代价选择的并行度,需要打开 auto dop 功能)、global parallel(parallel hint 或系统变量设置的并行度)。 avaiable_index_name t1 表可用的索引列表。这里除了索引表以外,还包括主表。如果没有合适的索引,计划会选择在主表上进行全表扫描。pruned_index_name 当前的查询基于优化器的规则,认为不应该使用的索引列表。OceanBase 数据库优化器的索引剪枝规则详见官网《OceanBase 数据库》文档 参考指南/性能调优/SQL 调优指南/SQL 优化/查询优化/访问路径/基于规则的路径选择 。 unstable_index_name 这个如果存在,则一定是被裁剪的主表路径,被裁剪通常是因为存在其他的索引路径 range 行数较小。 stats version t1 表统计信息版本号,如果值为 0,表示该表没有收集统计信息。为了保证计划生成正确,可以自动或者手动收集对应表的统计信息。dynamic sampling level 动态采样等级,如果值为 0,表示该表没有使用动态采样。参考指南/性能调优/SQL 调优指南/SQL 优化/优化器统计信息/统计信息收集方式/优化器动态采样 。 estimation method t1 表行数估计方式,可以是 DEFAULT(使用的默认统计信息,这种情况行数估计可能会不准,需要 DBA 介入优化)、STORAGE(使用存储层实时估行)、STATS(使用统计信息估行)。Plan Type 当前计划类型,可以是 LOCAL、REMOTE、DISTRIBUTED。具体含义详见本教程 ODP SQL 路由原理 中的 SQL 的计划类型 部分。 Note 生成该计划的一些备注信息。例如上面这个计划中的:Degree of Parallelisim is 1 because of table property 表示由于当前表的并行度设置为 1,所以当前查询的并行度被设置为 1。
EXPLAIN EXTENDED 在 EXPLAIN EXTENDED_NOADDR 的基础上,还会额外展示各个算子中涉及到的各个表达式的数据所存放的地址信息。通常技术支持同学和研发同学在排查 SQL 正确性问题时,会使用到这种展示模式。一般用户不需要关心各个表达式后面对应的地址信息,可以直接忽略。
explain EXTENDED select * from t1 where c1 > 10;输出如下:
+---------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+---------------------------------------------------------------------------------------------------------------------+
| =================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| --------------------------------------------------- |
| |0 |TABLE RANGE SCAN|t1(idx)|1 |7 | |
| =================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1(0x7fed4fe0df50)], [t1.c2(0x7fed4fe0e4c0)]), filter(nil), rowset=16 |
| access([t1.__pk_increment(0x7fed4fe0e9d0)], [t1.c1(0x7fed4fe0df50)], [t1.c2(0x7fed4fe0e4c0)]), partitions(p0) |
| is_index_back=true, is_global_index=false, |
| range_key([t1.c1(0x7fed4fe0df50)], [t1.__pk_increment(0x7fed4fe0e9d0)]), range(10,MAX ; MAX,MAX), |
| range_cond([t1.c1(0x7fed4fe0df50) > 10(0x7fed4fe0d800)]) |
| |
| ...... |
| |
+---------------------------------------------------------------------------------------------------------------------+执行计划中的算子介绍
常见的算子详见官网《OceanBase 数据库》文档 参考指南/性能调优/SQL 调优指南/SQL 执行计划/执行计划算子 章节。因为官网内容足够详细,所以本文档不再对各个算子逐一进行介绍。
说明
强烈推荐用户去了解一下其中最常见的 TABLE SCAN 算子 和 JOIN 算子 ,以及 TABLE SCAN 中的 DAS 执行 。
本文只会重点对一个被称为 EXCHANGE 的算子进行介绍。这个 EXCHANGE 算子在 OceanBase 数据库的分布式计划中很常见,且作用和含义不像其他算子那么容易理解,因此会在官网内容的基础上,对 EXCHANGE 算子进行一些补充。
EXCHANGE 算子是用于线程间进行数据交互的算子,一般都是成对出现的,数据源端有一个 OUT 算子,目的端会有一个 IN 算子。作用主要是:gather(数据汇聚)、transmit(数据转发)、re-partition(数据重分区),下面会对这三种作用逐一进行介绍。
EXCH-IN/OUT
EXCHANGE IN/EXCHANGE OUT 被用于将多个分区上的数据汇聚到一起,发送到查询所在的主节点上。
下面的查询中访问了 5 个分区(p0-p4)的数据:
CREATE TABLE t3 (c1 INT, c2 INT) PARTITION BY HASH(c1) PARTITIONS 5;执行 explain 命令查看执行计划
explain select * from t3 where c1 > 10;输出如下:
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| ============================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------------- |
| |0 |PX COORDINATOR | |1 |20 | |
| |1 |└─EXCHANGE OUT DISTR |:EX10000|1 |20 | |
| |2 | └─PX PARTITION ITERATOR| |1 |19 | |
| |3 | └─TABLE FULL SCAN |t3 |1 |19 | |
| ============================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([INTERNAL_FUNCTION(t3.c1, t3.c2)]), filter(nil), rowset=16 |
| 1 - output([INTERNAL_FUNCTION(t3.c1, t3.c2)]), filter(nil), rowset=16 |
| dop=1 |
| 2 - output([t3.c1], [t3.c2]), filter(nil), rowset=16 |
| force partition granule |
| 3 - output([t3.c1], [t3.c2]), filter([t3.c1 > 10]), rowset=16 |
| access([t3.c1], [t3.c2]), partitions(p[0-4]) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t3.__pk_increment]), range(MIN ; MAX)always true |
+------------------------------------------------------------------------------------+其中:
2 号算子 PX PARTITION ITERATOR 负责按照分区粒度迭代数据。granule iterator 算子的介绍详见官网《OceanBase 数据库》文档 参考指南/性能调优/SQL 调优指南/SQL 执行计划/执行计划算子/GI 。
1 号算子 EXCHANGE OUT DISTR 接受 2 号算子 PX PARTITION ITERATOR 产生的输出,并将数据传出。
0 号算子 PX COORDINATOR 接收多个分区上 1 号算子产生的输出,并将结果汇总输出给用户。PX COORDINATOR 是一种特殊的 EXCHANGE IN 算子,除了能够拉回远程的数据外,还负责调度子计划的执行。
EXCH-IN/OUT (REMOTE)
我们在 ODP SQL 路由原理 中介绍了执行计划主要分为三种不同的类型,分别是本地(Local) 计划、远程(Remote)计划和分布式(Distributed)计划。EXCHANGE IN REMOTE 和 EXCHANGE OUT REMOTE 算子就是在远程计划中用于将远程的数据(单个分区的数据)拉回本地。
例如我们创建了一个 1 – 1 – 1(3 Zone 3 节点)的环境,三个可用区分别是:zone1、zone2、zone3,对应的三个节点分别叫做 A、B、C。某个租户的 primary_zone 是 zone1,即这个租户下的所有表的主副本都会在 zone1 的 A 节点上。
本地计划
如果我们直连 A 节点,对两张非分区表进行计算,因为两表的主副本都在本机,就会生成如下的本地计划:
create table t1(c1 int, c2 int);
create table t2(c1 int, c2 int);
explain select * from t1, t2 where t1.c1 = t2.c1 and t1.c1 > 10;
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| ================================================= |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------- |
| |0 |HASH JOIN | |1 |9 | |
| |1 |├─TABLE FULL SCAN|t1 |1 |4 | |
| |2 |└─TABLE FULL SCAN|t2 |1 |4 | |
| ================================================= |
| Outputs & filters: 略 |远程计划
如果我们直连 B 节点,对两张非分区表进行计算,因为两表的主副本都不在本机,就会生成如下的远程计划:
explain select * from t1, t2 where t1.c1 = t2.c1 and t1.c1 > 10;输出如下:
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| ===================================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------------- |
| |0 |EXCHANGE IN REMOTE | |1 |11 | |
| |1 |└─EXCHANGE OUT REMOTE| |1 |10 | |
| |2 | └─HASH JOIN | |1 |9 | |
| |3 | ├─TABLE FULL SCAN|t1 |1 |4 | |
| |4 | └─TABLE FULL SCAN|t2 |1 |4 | |
| ===================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2], [t2.c1], [t2.c2]), filter(nil) |
| 1 - output([t1.c1], [t1.c2], [t2.c1], [t2.c2]), filter(nil) |
| 2 - output([t1.c1], [t1.c2], [t2.c1], [t2.c2]), filter(nil), rowset=16 |
| equal_conds([t1.c1 = t2.c1]), other_conds(nil) |
| 3 - output([t1.c1], [t1.c2]), filter([t1.c1 > 10]), rowset=16 |
| access([t1.c1], [t1.c2]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.__pk_increment]), range(MIN ; MAX)always true |
| 4 - output([t2.c1], [t2.c2]), filter([t2.c1 > 10]), rowset=16 |
| access([t2.c1], [t2.c2]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t2.__pk_increment]), range(MIN ; MAX)always true |
+------------------------------------------------------------------------------------+
23 rows in set远程计划中的 EXCHANGE IN REMOTE 和 EXCHANGE OUT REMOTE 算子用于将远程的数据(单个分区的数据)拉回本地。
由于待读取的数据在远程,执行计划中分配了 0 号算子和 1 号算子来拉取远程的数据。其中:
2 号 – 4 号算子在 A 机器上执行,负责读取存储层的数据,并完成 HASH JOIN 的计算。
1 号算子 EXCHANGE OUT REMOTE 也在 A 机器上执行,读取 2 号算子 HASH JOIN 计算的结果数据,并将数据传出给 0 号算子。
0 号算子 EXCHANGE IN REMOTE 在 B 机器上执行,接收 1 号算子产生的输出。
EXCH-IN/OUT (PKEY)
EXCH-IN/OUT (PKEY) 算子用于数据重分区。它通常用于二元算子(例如 JOIN 算子)中,将算子其中一个孩子节点(左支)的数据,按照另外一个孩子节点(右支)的分区方式进行重分区,然后将左支重分区后的数据发送给右支对应分区所在的节点,最终完成相应的计算。
如下示例中,该查询是对两个分区表的数据进行联接。
CREATE TABLE t1 (c1 INT, c2 INT) PARTITION BY HASH(c1) PARTITIONS 5;
CREATE TABLE t2 (c1 INT PRIMARY KEY, c2 INT) PARTITION BY HASH(c1) PARTITIONS 4;
EXPLAIN SELECT * FROM t1, t2 WHERE t1.c1 = t2.c1;
+---------------------------------------------------------------------------------------+
| Query Plan |
+---------------------------------------------------------------------------------------+
| ===================================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| --------------------------------------------------------------------- |
| |0 |PX COORDINATOR | |1 |38 | |
| |1 |└─EXCHANGE OUT DISTR |:EX10001|1 |37 | |
| |2 | └─HASH JOIN | |1 |36 | |
| |3 | ├─EXCHANGE IN DISTR | |1 |20 | |
| |4 | │ └─EXCHANGE OUT DISTR (PKEY)|:EX10000|1 |20 | |
| |5 | │ └─PX PARTITION ITERATOR | |1 |19 | |
| |6 | │ └─TABLE FULL SCAN |t1 |1 |19 | |
| |7 | └─PX PARTITION ITERATOR | |1 |16 | |
| |8 | └─TABLE FULL SCAN |t2 |1 |16 | |
| ===================================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t2.c1, t2.c2)]), filter(nil), rowset=16 |
| 1 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t2.c1, t2.c2)]), filter(nil), rowset=16 |
| dop=1 |
| 2 - output([t1.c1], [t2.c1], [t1.c2], [t2.c2]), filter(nil), rowset=16 |
| equal_conds([t1.c1 = t2.c1]), other_conds(nil) |
| 3 - output([t1.c1], [t1.c2]), filter(nil), rowset=16 |
| 4 - output([t1.c1], [t1.c2]), filter(nil), rowset=16 |
| (#keys=1, [t1.c1]), dop=1 |
| 5 - output([t1.c1], [t1.c2]), filter(nil), rowset=16 |
| force partition granule |
| 6 - output([t1.c1], [t1.c2]), filter(nil), rowset=16 |
| access([t1.c1], [t1.c2]), partitions(p[0-4]) |
| is_index_back=false, is_global_index=false, |
| range_key([t1.__pk_increment]), range(MIN ; MAX)always true |
| 7 - output([t2.c1], [t2.c2]), filter(nil), rowset=16 |
| affinitize, force partition granule |
| 8 - output([t2.c1], [t2.c2]), filter(nil), rowset=16 |
| access([t2.c1], [t2.c2]), partitions(p[0-3]) |
| is_index_back=false, is_global_index=false, |
| range_key([t2.c1]), range(MIN ; MAX)always true |
+---------------------------------------------------------------------------------------+执行计划将 t1 表的数据按照 t2 表的分区方式进行重分区:
4 号算子 EXCHANGE OUT DISTR (PKEY) 负责根据 t2 表的数据分区方式,以及查询的联接条件,确定 t1 表中的每一行数据应该发送到哪个节点才能完成与 t2 表对应分区的连接操作,并将 t1 表的各行数据发送到相应的节点。
3 号算子 EXCHANGE IN DISTR 负责在相应节点完成 t1 表数据的接收。
2 号算子 HASH JOIN 负责在各个节点,对 7 号算子迭代出的 t2 表各分区的数据,和 3 号算子接收到的 t1 表以 t2 表分区规则重分区后的对应分区数据,进行 JOIN 计算。
1 号算子 EXCHANGE OUT DISTR 负责把各节点、各分区 JOIN 之后的结果发送到 0 号算子。
0 号算子 PX COORDINATOR 负责接收各个节点 JOIN 的结果,并对结果进行汇总。
除了上述的 EXCH-IN/OUT (PKEY) 以外,优化器还会根据适合不同 SQL 的不同重分区方式,生成 EXCH-IN/OUT (HASH)、EXCH-IN/OUT (BC2HOST) 等算子,这里不再一一赘述。不同的数据重分布方式,详见官网《OceanBase 数据库》文档 参考指南/性能调优/SQL 调优指南/并行执行计划/并行执行计划简介 中 常见的并行执行中的数据分发方式 部分。
通过 Hint 生成指定计划
Hint 机制可以使优化器生成指定的执行计划。一般情况下,优化器会为用户查询选择最佳的执行计划,不需要用户使用 Hint 指定。但在某些场景下,优化器生成的执行计划可能不满足用户的要求,这时就需要用户使用 Hint 来指定生成某种执行计划。
Hint 语法
{ DELETE | INSERT | SELECT | UPDATE | REPLACE } /*+ [hint_text][,hint_text]... */例如下面这条查询语句,通过 /*+ PARALLEL(3)*/ 指定 SQL 的执行并行度为 3,通过 explain 就可以看到计划的 dop = 3,通过 explain EXTENDED_NOADDR 还可以看到计划中会展示一个 Note: Degree of Parallelism is 3 because of hint。
create t1 (c1 int, c2 int) PARTITION BY HASH(c1) PARTITIONS 5;
explain EXTENDED_NOADDR select /*+ PARALLEL(3) */* from t1 where c1 > 10;
+--------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------+
| ========================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ---------------------------------------------------------- |
| |0 |PX COORDINATOR | |1 |3 | |
| |1 |└─EXCHANGE OUT DISTR |:EX10000|1 |3 | |
| |2 | └─PX BLOCK ITERATOR | |1 |3 | |
| |3 | └─TABLE RANGE SCAN|t1(idx) |1 |3 | |
| ========================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([INTERNAL_FUNCTION(t1.c1, t1.c2)]), filter(nil), rowset=16 |
| 1 - output([INTERNAL_FUNCTION(t1.c1, t1.c2)]), filter(nil), rowset=16 |
| dop=3 |
| 2 - output([t1.c1], [t1.c2]), filter(nil), rowset=16 |
| 3 - output([t1.c1], [t1.c2]), filter(nil), rowset=16 |
| access([t1.__pk_increment], [t1.c1], [t1.c2]), partitions(p0) |
| is_index_back=true, is_global_index=false, |
| range_key([t1.c1], [t1.__pk_increment]), range(10,MAX ; MAX,MAX), |
| range_cond([t1.c1 > 10]) |
| Used Hint: |
| ------------------------------------- |
| /*+ |
| PARALLEL(3) |
| */ |
| |
| ...... |
| |
| Note: |
| Degree of Parallelism is 3 because of hint |
+--------------------------------------------------------------------------+Hint 从语法上看是一种特殊的 SQL 注释,所不同的是在注释的左标记后(/* 符号)增加了一个 +。 因为 Hint 是注释,所以如果因为语法出错的原因,导致 OBServer 服务端无法识别 SQL 语句中的 Hint,优化器会选择忽略用户指定的 Hint,去生成默认的执行计划。另外,Hint 只影响优化器生成的执行计划,不会影响 SQL 语句的语义。
说明
如果使用 MySQL 的 C 客户端执行带 Hint 的 SQL 语句,需要使用 -c 选项登录,否则 MySQL 客户端会将 Hint 作为注释从用户 SQL 语句中去除,导致系统无法收到用户 Hint。
Hint 参数
Hint 相关参数名称、语义和语法如下表所示。
名称 语法 语义 NO_REWRITE NO_REWRITE 禁止 SQL 改写。 READ_CONSISTENCY READ_CONSISTENCY(WEAK [STRONG]) 读一致性设置(弱/强)。 INDEX_HINT INDEX(table_name index_name) 设置表索引。 QUERY_TIMEOUT QUERY_TIMEOUT(INTNUM) 设置语句超时时间。 LOG_LEVEL LOG_LEVEL([‘]log_level[‘]) 设置日志级别,当设置模块级别语句时候,以第一个单引号(')作为开始,第二个单引号(')作为结束;例如 'DEBUG'。 LEADING LEADING([qb_name] TBL_NAME_LIST) 设置联接顺序。 ORDERED ORDERED 设置按照 SQL 中的顺序进行联接。 FULL FULL([qb_name] TBL_NAME) 设置表访问路径为主表等价于 INDEX(TBL_NAME PRIMARY)。 USE_PLAN_CACHE USE_PLAN_CACHE(NONE[DEFAULT]) 设置是否使用计划缓存:NONE:表示不使用计划缓存。DEFAULT:表示按照服务器本身的设置来决定是否使用计划缓存。 USE_MERGE USE_MERGE([qb_name] TBL_NAME_LIST) 设置指定表在作为右表时使用 Merge Join。 USE_HASH USE_HASH([qb_name] TBL_NAME_LIST) 设置指定表在作为右表时使用 Hash Join。 NO_USE_HASH NO_USE_HASH([qb_name] TBL_NAME_LIST) 设置指定表在作为右表时不使用 Hash Join。 USE_NL USE_NL([qb_name] TBL_NAME_LIST) 设置指定表在作为右表时使用 Nested Loop Join。 USE_BNL USE_BNL([qb_name] TBL_NAME_LIST) 设置指定表在作为右表时使用 Block Nested Loop Join USE_HASH_AGGREGATION USE_HASH_AGGREGATION([qb_name]) 设置聚合算法为 Hash。例如 Hash Group By 或者 Hash Distinct。 NO_USE_HASH_AGGREGATION NO_USE_HASH_AGGREGATION([qb_name]) 设置 Aggregate 方法不使用 Hash Aggregate,使用 Merge Group By 或者 Merge Distinct。 USE_LATE_MATERIALIZATION USE_LATE_MATERIALIZATION 设置使用晚期物化。 NO_USE_LATE_MATERIALIZATION NO_USE_LATE_MATERIALIZATION 设置不使用晚期物化。 TRACE_LOG TRACE_LOG 设置收集 Trace 记录用于 SHOW TRACE 展示。 QB_NAME QB_NAME( NAME ) 设置 Query Block 的名称。 PARALLEL PARALLEL(INTNUM) 设置分布式执行并行度。 TOPK TOPK(PRECISION MINIMUM_ROWS) 设置模糊查询的精度和最小行数。 其中 PRECSION 为整型,取值范围 [0,100],表示模糊查询的行数百分比;MINIMUM_ROWS 为最小返回行数。 MAX_CONCURRENT|MAX_CONCURRENT(n) 限制这个 SQL 文本的并发数。
说明
QB_NAME 语法是: @NAME
TBL_NAME 语法是: [db_name.]relation_name [qb_name]
QB_NAME 参数
在 DML 语句中,每一个 Query Block 都会有一个 QB_NAME(Query Block Name),可以由用户指定,也可以由系统自动生成。每一个 Query Block 都是一个语义上完整的查询语句,简单来看就是把 SQL 按 select、delete 这些词提取出来并结构化之后,按从左到右的方式标号。Query Block 的介绍详见官网《OceanBase 数据库》知识库 性能诊断和优化/SQL 诊断和优化/Query Block 介绍 。
在用户没有用 Hint 指定 QB_NAME 的时候,系统会按照 SEL$1、SEL$2、UPD$1、DEL$1 方式从左到右(实际也是 Resolver 的解析顺序)依次生成。
通过 QB_NAME 可以精确定位到每一个表,也可以在某处指定任意 Query Block 的行为。TBL_NAME 中的 QB_NAME 用于定位表,在 Hint 中最前面的 QB_NAME 用于定位 Hint 作用于哪一个 Query Block。
如下例所示,对于 SELECT *FROM t1, (SELECT* FROM t2 WHERE c2 = 1 LIMIT 5) WHERE t1.c1 = 1; 这条 SQL,按照默认规则:
第一个 Query Block SEL$1 是最外层的:SELECT * FROM t1, VIEW1 WHERE t1.c1 = 1。
第二个 Query Block SEL$2 是 VIEW1(即计划里的 ANONYMOUS_VIEW1):SELECT * FROM t2 WHERE c2 = 1 LIMIT 5。
优化器为 SEL$1 中的 t1 表选择走索引 t1_c1 路径,而为 SEL$2 中的 t2 表选择主表(Primary)访问。
CREATE TABLE t1(c1 INT, c2 INT, KEY t1_c1(c1));
CREATE TABLE t2(c1 INT, c2 INT, KEY t2_c1(c1));
EXPLAIN EXTENDED_NOADDR SELECT * FROM t1, (SELECT * FROM t2 WHERE c2 = 1 LIMIT 5) WHERE t1.c1 = 1;
+-----------------------------------------------------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------------------------------------------------+
| ====================================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ---------------------------------------------------------------------- |
| |0 |NESTED-LOOP JOIN CARTESIAN | |1 |11 | |
| |1 |├─TABLE RANGE SCAN |t1(t1_c1) |1 |7 | |
| |2 |└─MATERIAL | |1 |4 | |
| |3 | └─SUBPLAN SCAN |ANONYMOUS_VIEW1|1 |4 | |
| |4 | └─TABLE FULL SCAN |t2 |1 |4 | |
| ====================================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2], [.c1], [.c2]), filter(nil), rowset=16 |
| conds(nil), nl_params_(nil), use_batch=false |
| 1 - output([t1.c1], [t1.c2]), filter(nil), rowset=16 |
| access([t1.__pk_increment], [t1.c1], [t1.c2]), partitions(p0) |
| is_index_back=true, is_global_index=false, |
| range_key([t1.c1], [t1.__pk_increment]), range(1,MIN ; 1,MAX), |
| range_cond([t1.c1 = 1]) |
| 2 - output([.c1], [.c2]), filter(nil), rowset=16 |
| 3 - output([.c1], [.c2]), filter(nil), rowset=16 |
| access([.c1], [.c2]) |
| 4 - output([t2.c1], [t2.c2]), filter([t2.c2 = 1]), rowset=16 |
| access([t2.c2], [t2.c1]), partitions(p0) |
| limit(5), offset(nil), is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t2.__pk_increment]), range(MIN ; MAX)always true |
| Used Hint: |
| ------------------------------------- |
| /*+ |
| |
| */ |
| Qb name trace: |
| ------------------------------------- |
| stmt_id:0, stmt_type:T_EXPLAIN |
| stmt_id:1, SEL$1 |
| stmt_id:2, SEL$2 |
| Outline Data: |
| ------------------------------------- |
| /*+ |
| BEGIN_OUTLINE_DATA |
| LEADING(@"SEL$1" ("test"."t1"@"SEL$1" "ANONYMOUS_VIEW1"@"SEL$1")) |
| USE_NL(@"SEL$1" "ANONYMOUS_VIEW1"@"SEL$1") |
| USE_NL_MATERIALIZATION(@"SEL$1" "ANONYMOUS_VIEW1"@"SEL$1") |
| INDEX(@"SEL$1" "test"."t1"@"SEL$1" "t1_c1") |
| FULL(@"SEL$2" "test"."t2"@"SEL$2") |
| OPTIMIZER_FEATURES_ENABLE('4.0.0.0') |
| END_OUTLINE_DATA |
| */ |
| ...... |
+-----------------------------------------------------------------------------------------------------------+如果 SQL 通过 Hint 来指定 SEL$1 的 t1 表走主表,SEL$2 的 t2 表走索引,示例如下:
EXPLAIN EXTENDED_NOADDR
SELECT /*+ INDEX(@SEL$1 t1 PRIMARY) INDEX(@SEL$2 t2 t2_c1) */ *
FROM t1 , (SELECT * FROM t2 WHERE c2 = 1 LIMIT 5) WHERE t1.c1 = 1;
+----------------------------------------------------------------------------------------------------------+
| Query Plan |
+----------------------------------------------------------------------------------------------------------+
| ====================================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ---------------------------------------------------------------------- |
| |0 |NESTED-LOOP JOIN CARTESIAN | |1 |11 | |
| |1 |├─TABLE FULL SCAN |t1 |1 |4 | |
| |2 |└─MATERIAL | |1 |7 | |
| |3 | └─SUBPLAN SCAN |ANONYMOUS_VIEW1|1 |7 | |
| |4 | └─TABLE FULL SCAN |t2(t2_c1) |1 |7 | |
| ====================================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2], [.c1], [.c2]), filter(nil), rowset=16 |
| conds(nil), nl_params_(nil), use_batch=false |
| 1 - output([t1.c1], [t1.c2]), filter([t1.c1 = 1]), rowset=16 |
| access([t1.c1], [t1.c2]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.__pk_increment]), range(MIN ; MAX)always true |
| 2 - output([.c1], [.c2]), filter(nil), rowset=16 |
| 3 - output([.c1], [.c2]), filter(nil), rowset=16 |
| access([.c1], [.c2]) |
| 4 - output([t2.c1], [t2.c2]), filter([t2.c2 = 1]), rowset=16 |
| access([t2.__pk_increment], [t2.c2], [t2.c1]), partitions(p0) |
| limit(5), offset(nil), is_index_back=true, is_global_index=false, filter_before_indexback[false], |
| range_key([t2.c1], [t2.__pk_increment]), range(MIN,MIN ; MAX,MAX)always true |
| Used Hint: |
| ------------------------------------- |
| /*+ |
| |
| INDEX("t1" "primary") |
| INDEX(@"SEL$2" "t2" "t2_c1") |
| */ |
| Qb name trace: |
| ------------------------------------- |
| stmt_id:0, stmt_type:T_EXPLAIN |
| stmt_id:1, SEL$1 |
| stmt_id:2, SEL$2 |
| Outline Data: |
| ------------------------------------- |
| /*+ |
| BEGIN_OUTLINE_DATA |
| LEADING(@"SEL$1" ("test"."t1"@"SEL$1" "ANONYMOUS_VIEW1"@"SEL$1")) |
| USE_NL(@"SEL$1" "ANONYMOUS_VIEW1"@"SEL$1") |
| USE_NL_MATERIALIZATION(@"SEL$1" "ANONYMOUS_VIEW1"@"SEL$1") |
| FULL(@"SEL$1" "test"."t1"@"SEL$1") |
| INDEX(@"SEL$2" "test"."t2"@"SEL$2" "t2_c1") |
| OPTIMIZER_FEATURES_ENABLE('4.0.0.0') |
| END_OUTLINE_DATA |
| */ |
| ...... |
+----------------------------------------------------------------------------------------------------------+读者可以自行研究一下,在加这个 Hint /*+ INDEX(t1 PRIMARY) INDEX(@SEL$2 t2 t2_c1)*/ 前后,计划 Query Plan 部分和 Outline Data 部分有什么变化,以及变化是否是符合预期的?
上述示例中的 Hint 也可以写成如下三种方式,这几种写法都是等价的:
SELECT /*+INDEX(@SEL$1 t1 PRIMARY) INDEX(@SEL$2 t2 t2_c1)*/ * FROM t1 , (SELECT * FROM t2 WHERE c2 = 1 LIMIT 5) WHERE t1.c1 = 1; SELECT /*+INDEX(t1 PRIMARY) INDEX(@SEL$2 t2@SEL$2 t2_c1)*/ * FROM t1 , (SELECT * FROM t2 WHERE c2 = 1 LIMIT 5) WHERE t1.c1 = 1; SELECT /*+INDEX(t1 PRIMARY)*/ * FROM t1 , (SELECT /*+INDEX(t2 t2_c1)*/ * FROM t2 WHERE c2 = 1 LIMIT 5) WHERE t1.c1 = 1;Hint 使用规则
Hint 的一般使用规则如下:
对于没有指定 Query Block 的 Hint,表明作用于本 Query Block。
示例 1:由于 Hint 写在 Query Block 1,但 Hint 中的 t2 表只出现在 Query Block 2,且优化器无法通过改写 SQL 将 SEL$2 中的 t2 表提升到 SEL$1 中,则 Hint 无法生效。 EXPLAIN SELECT /*+INDEX(t2 t2_c1)*/ * FROM t1 , (SELECT * FROM t2 WHERE c2 = 1 LIMIT 5) WHERE t1.c1 = 1; 输出如下: +-----------------------------------------------------------------------------------------------------------+ | Query Plan | +-----------------------------------------------------------------------------------------------------------+ | ====================================================================== | | |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| | | ---------------------------------------------------------------------- | | |0 |NESTED-LOOP JOIN CARTESIAN | |1 |11 | | | |1 |├─TABLE RANGE SCAN |t1(t1_c1) |1 |7 | | | |2 |└─MATERIAL | |1 |4 | | | |3 | └─SUBPLAN SCAN |ANONYMOUS_VIEW1|1 |4 | | | |4 | └─TABLE FULL SCAN |t2 |1 |4 | | | ====================================================================== | | ...... | +-----------------------------------------------------------------------------------------------------------+
示例 2:如果 SQL 可以通过优化器改写将 t2 表提升到 SEL$1,则 Hint 生效。如下面这个计划所示,原本的 SQL 明显是被改写成了一条不存在匿名视图的 SQL:SELECT /*+INDEX(t2 t2_c1)*/ * FROM t1, t2 WHERE t1.c1 = 1 and t2.c2 = 1;,在这条被改写之后的 SQL 中,t2 表被提升到了最外层的 SEL$1 里,所以 Hint 会生效。 EXPLAIN SELECT /*+ INDEX(t2 t2_c1) */ * FROM t1 , (SELECT * FROM t2 WHERE c2 = 1) WHERE t1.c1 = 1; 输出如下: +------------------------------------------------------------------------------------+ | Query Plan | +------------------------------------------------------------------------------------+ | ================================================================ | | |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| | | ---------------------------------------------------------------- | | |0 |NESTED-LOOP JOIN CARTESIAN | |1 |13 | | | |1 |├─TABLE RANGE SCAN |t1(t1_c1)|1 |7 | | | |2 |└─MATERIAL | |1 |7 | | | |3 | └─TABLE FULL SCAN |t2(t2_c1)|1 |7 | | | ================================================================ | | Outputs & filters: | | ------------------------------------- | | 0 - output([t1.c1], [t1.c2], [t2.c1], [t2.c2]), filter(nil), rowset=16 | | conds(nil), nl_params_(nil), use_batch=false | | 1 - output([t1.c1], [t1.c2]), filter(nil), rowset=16 | | access([t1.__pk_increment], [t1.c1], [t1.c2]), partitions(p0) | | is_index_back=true, is_global_index=false, | | range_key([t1.c1], [t1.__pk_increment]), range(1,MIN ; 1,MAX), | | range_cond([t1.c1 = 1]) | | 2 - output([t2.c1], [t2.c2]), filter(nil), rowset=16 | | 3 - output([t2.c2], [t2.c1]), filter([t2.c2 = 1]), rowset=16 | | access([t2.__pk_increment], [t2.c2], [t2.c1]), partitions(p0) | | is_index_back=true, is_global_index=false, filter_before_indexback[false], | | range_key([t2.c1], [t2.__pk_increment]), range(MIN,MIN ; MAX,MAX)always true | +------------------------------------------------------------------------------------+
如果指定表行为,但在本 Query Block 中没有找到该表,或者发生冲突,那么 Hint 都将无效。
常用 Hint
与其他数据库的行为相比,OceanBase 数据库优化器是动态规划的,已经考虑了所有可能的最优路径,Hint 主要作用是指定优化器的行为,并按照 Hint 执行 SQL 查询。下面会介绍用户最为常用的一些 Hint。
INDEX Hint
INDEX Hint 的语法如下:
SELECT/*+ INDEX(table_name index_name) */ * FROM table_name;在 SQL 语句中,表名存在别名即 table_name [AS] alias,必须写表别名,才能使 INDEX 生效。示例如下:
create table t1(c1 int, c2 int, c3 int);
create index idx1 on t1(c1);
create index idx2 on t1(c2);
-- 插入 1000 行测试数据
insert into t1 with recursive cte(n) as (select 1 from dual union all select n + 1 from cte where n < 1000) select n, mod(n, 3), n from cte;
-- 收集指定表 t1 的统计信息
analyze table t1 COMPUTE STATISTICS for all columns size 128;
-- 对于这 1000 行测试数据的数据特征,c1 = 1 过滤性优于 c2 = 1
-- 所以在没有 index hint 或者 hint 不生效时,优化器在生成计划的过程中,默认会优先选择使用 idx1 这个索引
explain select * from t1 where c1 = 1 and c2 = 1;
+-----------------------------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------------------------+
| ==================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ---------------------------------------------------- |
| |0 |TABLE RANGE SCAN|t1(idx1)|1 |7 | |
| ==================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2], [t1.c3]), filter([t1.c2 = 1]), rowset=16 |
| access([t1.__pk_increment], [t1.c1], [t1.c2], [t1.c3]), partitions(p0) |
| is_index_back=true, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.c1], [t1.__pk_increment]), range(1,MIN ; 1,MAX), |
| range_cond([t1.c1 = 1]) |
+-----------------------------------------------------------------------------------+
-- 生效的 index hint
explain select /*+index(t idx2)*/ * from t1 as t where c1 = 1 and c2 = 1;
+-----------------------------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------------------------+
| =================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| --------------------------------------------------- |
| |0 |TABLE RANGE SCAN|t(idx2)|1 |871 | |
| =================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t.c1], [t.c2], [t.c3]), filter([t.c1 = 1]), rowset=16 |
| access([t.__pk_increment], [t.c1], [t.c2], [t.c3]), partitions(p0) |
| is_index_back=true, is_global_index=false, filter_before_indexback[false], |
| range_key([t.c2], [t.__pk_increment]), range(1,MIN ; 1,MAX), |
| range_cond([t.c2 = 1]) |
+-----------------------------------------------------------------------------------+
-- 不生效的 index,因为 t1 已经被赋予了一个别名 t
explain select /*+index(t1 idx2)*/ * from t1 t where c1 = 1 and c2 = 1;
+-----------------------------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------------------------+
| =================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| --------------------------------------------------- |
| |0 |TABLE RANGE SCAN|t(idx1)|1 |7 | |
| =================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t.c1], [t.c2], [t.c3]), filter([t.c2 = 1]), rowset=16 |
| access([t.__pk_increment], [t.c1], [t.c2], [t.c3]), partitions(p0) |
| is_index_back=true, is_global_index=false, filter_before_indexback[false], |
| range_key([t.c1], [t.__pk_increment]), range(1,MIN ; 1,MAX), |
| range_cond([t.c1 = 1]) |
+-----------------------------------------------------------------------------------+FULL Hint
FULL Hint 的语法是用于指定表使用主表扫描,等价于 INDEX Hint /*+ INDEX(table_name PRIMARY)*/。
示例如下:
create table t1(c1 int, c2 int, c3 int);
create index idx1 on t1(c1);
-- c1 上有一个索引 idx1,且过滤条件中的列和结果列都是 c1,所以优化器会默认选择使用 idx1
explain select c1 from t1 where c1 = 1;
+-----------------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------------+
| ==================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ---------------------------------------------------- |
| |0 |TABLE RANGE SCAN|t1(idx1)|1 |4 | |
| ==================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1]), filter(nil), rowset=4 |
| access([t1.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t1.c1], [t1.__pk_increment]), range(1,MIN ; 1,MAX), |
| range_cond([t1.c1 = 1]) |
+-----------------------------------------------------------------------+
-- 通过 hint 让计划不走索引,变为全表扫描
explain select /*+ FULL(t1) */ c1 from t1 where c1 = 1;
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| =============================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------- |
| |0 |TABLE FULL SCAN|t1 |1 |4 | |
| =============================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1]), filter([t1.c1 = 1]), rowset=4 |
| access([t1.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.__pk_increment]), range(MIN ; MAX)always true |
+------------------------------------------------------------------------------------+
-- 通过 hint 让计划不走索引,变为全表扫描,和上面那条 SQL 等价
explain select /*+ index(t1 PRIMARY) */ c1 from t1 where c1 = 1;
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| =============================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------- |
| |0 |TABLE FULL SCAN|t1 |1 |4 | |
| =============================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1]), filter([t1.c1 = 1]), rowset=4 |
| access([t1.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.__pk_increment]), range(MIN ; MAX)always true |
+------------------------------------------------------------------------------------+LEADING Hint
LEADING Hint 可以指定表的联接顺序。语法是:/*+ LEADING(table_name_list)*/。在 table_name_list 中可以使用 () 表示内部各表的联接优先级,指定复杂的联接顺序,比 ordered 有更大的灵活性。示例如下:
EXPLAIN BASIC SELECT /*+LEADING(d c b a)*/ * FROM t1 a, t1 b, t1 c, t1 d;
+------------------------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------------------------+
| ========================================= |
| |ID|OPERATOR |NAME| |
| ----------------------------------------- |
| |0 |NESTED-LOOP JOIN CARTESIAN | | |
| |1 |├─NESTED-LOOP JOIN CARTESIAN | | |
| |2 |│ ├─NESTED-LOOP JOIN CARTESIAN | | |
| |3 |│ │ ├─TABLE FULL SCAN |d | |
| |4 |│ │ └─MATERIAL | | |
| |5 |│ │ └─TABLE FULL SCAN |c | |
| |6 |│ └─MATERIAL | | |
| |7 |│ └─TABLE FULL SCAN |b | |
| |8 |└─MATERIAL | | |
| |9 | └─TABLE FULL SCAN |a | |
| ========================================= |
+------------------------------------------------------------------------------------------------------+
EXPLAIN BASIC SELECT /*+LEADING((d c) (b a))*/ * FROM t1 a, t1 b, t1 c, t1 d;
+------------------------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------------------------+
| ========================================= |
| |ID|OPERATOR |NAME| |
| ----------------------------------------- |
| |0 |NESTED-LOOP JOIN CARTESIAN | | |
| |1 |├─NESTED-LOOP JOIN CARTESIAN | | |
| |2 |│ ├─TABLE FULL SCAN |d | |
| |3 |│ └─MATERIAL | | |
| |4 |│ └─TABLE FULL SCAN |c | |
| |5 |└─MATERIAL | | |
| |6 | └─NESTED-LOOP JOIN CARTESIAN | | |
| |7 | ├─TABLE FULL SCAN |b | |
| |8 | └─MATERIAL | | |
| |9 | └─TABLE FULL SCAN |a | |
| ========================================= |
+------------------------------------------------------------------------------------------------------+
EXPLAIN BASIC SELECT /*+LEADING((d c b) a))*/ * FROM t1 a, t1 b, t1 c, t1 d;
+------------------------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------------------------+
| ========================================= |
| |ID|OPERATOR |NAME| |
| ----------------------------------------- |
| |0 |NESTED-LOOP JOIN CARTESIAN | | |
| |1 |├─NESTED-LOOP JOIN CARTESIAN | | |
| |2 |│ ├─NESTED-LOOP JOIN CARTESIAN | | |
| |3 |│ │ ├─TABLE FULL SCAN |d | |
| |4 |│ │ └─MATERIAL | | |
| |5 |│ │ └─TABLE FULL SCAN |c | |
| |6 |│ └─MATERIAL | | |
| |7 |│ └─TABLE FULL SCAN |b | |
| |8 |└─MATERIAL | | |
| |9 | └─TABLE FULL SCAN |a | |
| ========================================= |
+------------------------------------------------------------------------------------------------------+为确保按照用户指定的顺序进行联接,LEADING Hint 的检查比较严格,如果发现 Hint 指定的 table_name 不存在,LEADING Hint 失效;如果发现 Hint 中存在重复表,LEADING Hint 失效。如果在 Optimizer 联接期间,按 table_id 无法在 From Items 中找到对应的表,则可能发生改写,那么该表及后面的表指定的 JOIN 顺序失效,该表前面的 JOIN 顺序依然有效。
说明
如果同时使用 ordered 和 leading,则仅 ordered 生效。
USE_NL Hint
和 join 相关的 Hint 的基本结构如下:join_hint_name ( @ qb_name table_name_list),基本语义为,当联接的右表匹配 table_name_list 时,按照 Hint 语义生成计划。一般需要使用 LEADING Hint 指定联接顺序,使 table_name_list 中的表为右表,否则 Hint 会随着联接顺序变化而失效。
其中 table_name_list 可有以下形式:
单表 use_nl ( t1 ):以 t1 为右表时使用 Nested Loop Join。
多个单表 use_nl ( t1 t2 ... ):以 t1 或 t2 等为右表时使用 Nested Loop Join。
多表 use_nl ((t1 t2)):以 t1 join t2 为右表时使用 Nested Loop Join,忽略 t1/t2 连接顺序和方法。
多组表 use_nl (t1 (t2 t3) (t4 t5 t6) ... ):以 t1/t2 join t3/t4 join t5 join t6 等表为右表时使用 Nested Loop Join。
在 USE_NL 指定的表是 NLJ 的右表,在联接的时候会使用 Nested Loop Join 算法,语法是:/*+ USE_NL(table_name_list)*/。示例如下:
CREATE TABLE t0(c1 INT, c2 INT, c3 INT);
CREATE TABLE t1(c1 INT, c2 INT, c3 INT);
CREATE TABLE t2(c1 INT, c2 INT, c3 INT);
-- 如果想让 join 的顺序是 t0 join t1,join 为 nest loop join,则应该这样写 hint:
EXPLAIN BASIC SELECT /*+ LEADING(t0 t1) USE_NL(t1) */ * FROM t0, t1 WHERE t0.c1 = t1.c1;
+--------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------+
| ============================= |
| |ID|OPERATOR |NAME| |
| ----------------------------- |
| |0 |NESTED-LOOP JOIN | | |
| |1 |├─TABLE FULL SCAN |t0 | |
| |2 |└─MATERIAL | | |
| |3 | └─TABLE FULL SCAN|t1 | |
| ============================= |
+--------------------------------------------------------------------------------------------+
-- 如果想让 join 的顺序是 t0 join (t1 join t2),且想让最外层的 join 为 nest loop join,则应该这样写 hint:
EXPLAIN BASIC SELECT /*+ LEADING(t0 (t1 t2)) USE_NL((t1 t2)) */ * FROM t0, t1, t2 WHERE t0.c1 = t1.c1 AND t0.c1 = t2.c1;
+-----------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------------------------------------------------------------+
| =============================== |
| |ID|OPERATOR |NAME| |
| ------------------------------- |
| |0 |NESTED-LOOP JOIN | | |
| |1 |├─TABLE FULL SCAN |t0 | |
| |2 |└─MATERIAL | | |
| |3 | └─HASH JOIN | | |
| |4 | ├─TABLE FULL SCAN|t1 | |
| |5 | └─TABLE FULL SCAN|t2 | |
| =============================== |
+-----------------------------------------------------------------------------------------------------------------------+
注意
USE_NL、USE_HASH、USE_MERGE 这三个 hint 往往会配合 LEADING 这个 hint 一起使用。因为当 join 的右表匹配 table_name_list 时,才会按照 hint 语义生成计划。
前面这句话理解起来可能不是那么直观,接下来,我们来举一个最简单的小例子。假设用户希望对一条 SQL:SELECT * FROM t1, t2 WHERE t1.c1 = t2.c1; 中 t1 join t2 对应计划中的 join 计算方式进行干预。
原本的计划空间有六种,分别是:
t1 nest loop join t2
t1 hash join t2
t1 merge join t2
t2 nest loop join t1
t2 hash join t1
t2 merge join t1
如果加了 hint:/*+ USE_NL(t1)*/,则计划空间减少为四种,分别是:
t1 nest loop join t2
t1 hash join t2
t1 merge join t2
t2 nest loop join t1
因为计划空间中,只有当 t1 为 join 的右表时,才会按照 hint 生成 t2 nest loop join t1 的计划;当 t1 为 join 的左表时,则不受这个 hint 的影响。
如果加了 hint:/*+ LEADING(t2 t1) USE_NL(t1)*/,计划空间就只有确定的一种:t2 nest loop join t1
USE_HASH Hint
和 USE_NL 类似,USE_HASH 指定表作为 HJ 的右表,在联接的时候使用 Hash Join 算法,语法是:/*+ USE_HASH(table_name_list)*/。示例如下:
CREATE TABLE t0(c1 INT, c2 INT, c3 INT);
CREATE TABLE t1(c1 INT, c2 INT, c3 INT);
EXPLAIN BASIC SELECT /*+LEADING(t0 t1) USE_HASH(t1)*/ * FROM t0, t1 WHERE t0.c1 = t1.c1;
+--------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------+
| =========================== |
| |ID|OPERATOR |NAME| |
| --------------------------- |
| |0 |HASH JOIN | | |
| |1 |├─TABLE FULL SCAN|t0 | |
| |2 |└─TABLE FULL SCAN|t1 | |
| =========================== |
+--------------------------------------------------------------------------------------------+USE_MERGE Hint
和 USE_NL 类似,USE_MERGE 指定表作为 MJ 的右表,在联接的时候使用 Merge Join 算法,语法是:/*+ USE_MERGE(table_name_list)*/。示例如下:
CREATE TABLE t0(c1 INT, c2 INT, c3 INT);
CREATE TABLE t1(c1 INT, c2 INT, c3 INT);
EXPLAIN BASIC SELECT /*+LEADING(t0 t1) USE_MERGE(t1)*/ * FROM t0, t1 WHERE t0.c1 = t1.c1;
+--------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------+
| ============================= |
| |ID|OPERATOR |NAME| |
| ----------------------------- |
| |0 |MERGE JOIN | | |
| |1 |├─SORT | | |
| |2 |│ └─TABLE FULL SCAN|t0 | |
| |3 |└─SORT | | |
| |4 | └─TABLE FULL SCAN|t1 | |
| ============================= |
+--------------------------------------------------------------------------------------------+
说明
OceanBase 数据库中 Merge Join 必须有等值的 join 联接条件。如果无等值条件的两个表联接,USE_MERGE 会失效。
PARALLEL Hint
PARALLEL 指定语句级别的并行度。语法是:/*+ PARALLEL(n)*/。其中 n 为整数,表示 SQL 的全局并行度。示例如下:
CREATE TABLE tbl1 (col1 INT) PARTITION BY HASH(col1) ;
EXPLAIN BASIC SELECT /*+ PARALLEL(5) */ * FROM tbl1;
+----------------------------------------------------------------------+
| Query Plan |
+----------------------------------------------------------------------+
| =================================== |
| |ID|OPERATOR |NAME | |
| ----------------------------------- |
| |0 |PX COORDINATOR | | |
| |1 |└─EXCHANGE OUT DISTR |:EX10000| |
| |2 | └─PX BLOCK ITERATOR| | |
| |3 | └─TABLE FULL SCAN|tbl1 | |
| =================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([INTERNAL_FUNCTION(tbl1.col1)]), filter(nil), rowset=16 |
| 1 - output([INTERNAL_FUNCTION(tbl1.col1)]), filter(nil), rowset=16 |
| dop=5 |
| 2 - output([tbl1.col1]), filter(nil), rowset=16 |
| 3 - output([tbl1.col1]), filter(nil), rowset=16 |
| access([tbl1.col1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([tbl1.__pk_increment]), range(MIN ; MAX)always true |
+----------------------------------------------------------------------+计划中显示的 dop=5 表明 hint 已经生效。
OceanBase 数据库同时也支持表级别的 PARALLEL Hint,语法是:/*+ PARALLEL(table_name n)*/。示例如下:
CREATE TABLE t1 (c1 INT, c2 INT) PARTITION BY HASH(c1) PARTITIONS 5;
CREATE TABLE t2 (c1 INT PRIMARY KEY, c2 INT) PARTITION BY HASH(c1) PARTITIONS 4;
EXPLAIN SELECT /*+ PARALLEL(3) PARALLEL(t2 5)*/* FROM t1, t2 WHERE t1.c1 = t2.c1;
EXPLAIN SELECT /*+ PARALLEL(3) PARALLEL(t1 4) PARALLEL(t2 5)*/* FROM t1, t2 WHERE t1.c1 = t2.c1;
+---------------------------------------------------------------------------------------+
| Query Plan |
+---------------------------------------------------------------------------------------+
| ======================================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------------------------------- |
| |0 |PX COORDINATOR | |1 |9 | |
| |1 |└─EXCHANGE OUT DISTR |:EX10001|1 |9 | |
| |2 | └─HASH JOIN | |1 |9 | |
| |3 | ├─PART JOIN FILTER CREATE |:RF0000 |1 |5 | |
| |4 | │ └─PX PARTITION ITERATOR | |1 |5 | |
| |5 | │ └─TABLE FULL SCAN |t1 |1 |5 | |
| |6 | └─EXCHANGE IN DISTR | |1 |4 | |
| |7 | └─EXCHANGE OUT DISTR (PKEY) |:EX10000|1 |4 | |
| |8 | └─PX BLOCK HASH JOIN-FILTER|:RF0000 |1 |4 | |
| |9 | └─TABLE FULL SCAN |t2 |1 |4 | |
| ======================================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t2.c1, t2.c2)]), filter(nil), rowset=16 |
| 1 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t2.c1, t2.c2)]), filter(nil), rowset=16 |
| dop=4 |
| 2 - output([t1.c1], [t2.c1], [t1.c2], [t2.c2]), filter(nil), rowset=16 |
| equal_conds([t1.c1 = t2.c1]), other_conds(nil) |
| 3 - output([t1.c1], [t1.c2]), filter(nil), rowset=16 |
| RF_TYPE(bloom), RF_EXPR[calc_tablet_id(t1.c1)] |
| 4 - output([t1.c1], [t1.c2]), filter(nil), rowset=16 |
| affinitize |
| 5 - output([t1.c1], [t1.c2]), filter(nil), rowset=16 |
| access([t1.c1], [t1.c2]), partitions(p[0-4]) |
| is_index_back=false, is_global_index=false, |
| range_key([t1.__pk_increment]), range(MIN ; MAX)always true |
| 6 - output([t2.c1], [t2.c2]), filter(nil), rowset=16 |
| 7 - output([t2.c1], [t2.c2]), filter(nil), rowset=16 |
| (#keys=1, [t2.c1]), dop=5 |
| 8 - output([t2.c1], [t2.c2]), filter(nil), rowset=16 |
| 9 - output([t2.c1], [t2.c2]), filter(nil), rowset=16 |
| access([t2.c1], [t2.c2]), partitions(p[0-3]) |
| is_index_back=false, is_global_index=false, |
| range_key([t2.c1]), range(MIN ; MAX)always true |
+---------------------------------------------------------------------------------------+READ_CONSISTENCY(WEAK) Hint
READ_CONSISTENCY Hint 用于指定 SQL 的读一致性级别为弱一致性,语法是:/*+ READ_CONSISTENCY(WEAK)*/。示例如下:
-- 读取 t1 表备副本上的数据
SELECT /*+ READ_CONSISTENCY(WEAK) */ * FROM t1;对于实时性要求不高的偏 AP 类请求,为了实现 AP 业务和 TP 业务的读写分离,减少 AP 请求对主副本的影响,可以设置弱一致性读。设置弱一致性读的 hint 之后,读操作会到备副本上执行。弱一致性读的概念详见官网《OceanBase 数据库》文档 参考指南/系统原理/事务管理/事务并发和一致性/弱一致性读 。
QUERY_TIMEOUT Hint
QUERY_TIMEOUT Hint 用于设置查询语句的超时时间,语法是:/*+ query_timeout(n)*/,其中的 n 是整数,单位是微秒(us)。示例如下:
-- 指定这条 SQL 执行的超时时间为 100000000 微秒,即 100 秒。
SELECT /*+ query_timeout(100000000) */ * FROM t1;
说明
用户可以通过执行 SHOW VARIABLES LIKE 'ob_query_timeout'; 查看默认的 SQL 超时时间。
OceanBase 数据库除了支持通过 hint 修改 SQL 级别的 SQL 超时时间,还支持通过执行 SET SESSION ob_query_timeout = 100000000; 修改会话(session)级别的SQL 超时时间,支持通过执行 SET GLOBAL ob_query_timeout = 100000000; 修改租户级别的 SQL 超时时间。
通过 Outline 进行计划绑定
通过对某条 SQL 创建 Outline 可实现计划绑定。
在生产系统上线前,可以直接在 SQL 语句中添加 Hint,控制优化器按 Hint 指定的行为进行计划生成。
但对于已上线的业务,如果出现优化器选择的计划不够优时,则需要在线进行计划绑定,无需业务对 SQL 进行更改。而是通过 DDL 操作将一组 Hint 加入到特定的 SQL 中,从而使优化器根据指定的一组 Hint,对该 SQL 生成更优计划。该组 Hint 称为 Outline。
Outline 相关的字典视图
Outline 视图为 DBA_OB_OUTLINES,其字段说明如下表所示。
字段名称 类型(MySQL 模式) 类型(Oracle 模式) 描述 CREATE_TIME TIMESTAMP(6) TIMESTAMP(6) 创建时间戳 MODIFY_TIME TIMESTAMP(6) TIMESTAMP(6) 修改时间戳 TENANT_ID BIGINT(20) NUMBER(38) 租户 ID DATABASE_ID BIGINT(20) NUMBER(38) 数据库 ID OUTLINE_ID BIGINT(20) NUMBER(38) Outline ID DATABASE_NAME VARCHAR2(128) VARCHAR2(128) 数据库名称 OUTLINE_NAME VARCHAR2(128) VARCHAR2(128) Outline 名称 VISIBLE_SIGNATURE LONGTEXT CLOB Signature 的反序列化结果,为了便于查看 Signature 的信息。 SQL_TEXT LONGTEXT CLOB 创建 Outline 时,在 ON 子句中指定的 SQL。 OUTLINE_TARGET LONGTEXT CLOB 创建 Outline 时,在 TO 子句中指定的 SQL。 OUTLINE_SQL LONGTEXT CLOB 具有完整 Outline 信息的 SQL SQL_ID VARCHAR2(32) VARCHAR2(32) SQL 标识符 OUTLINE_CONTENT LONGTEXT CLOB 完整的执行计划 Outline 信息
创建 Outline
OceanBase 数据库支持通过两种方式创建 Outline,一种是通过 SQL_TEXT (用户执行的带参数的原始语句),另一种是通过 SQL_ID。
注意
创建 Outline 需要进入对应的数据库下执行。
使用 SQL_TEXT 创建 Outline
使用 SQL_TEXT 创建 Outline 后,会生成一个 Key-Value 对存储在 Map 中,其中 Key 为绑定的 SQL 参数化后的文本,Value 为绑定的 Hint。具体参数化原则,详见官网《OceanBase 数据库》文档 参考指南/性能调优/SQL 调优指南/SQL 执行计划/快速参数化 。
使用 SQL_TEXT 创建 Outline 的语法如下:
CREATE [OR REPLACE] OUTLINE <outline_name> ON <stmt>;
指定 OR REPLACE 后,可以对已经存在执行计划进行替换。
其中 stmt 一般为一个带有 Hint 和原始参数的 DML 语句。示例如下:
CREATE OUTLINE outline1 ON
SELECT /*+NO_REWRITE*/ *
FROM tbl1
WHERE col1 = 4 AND col2 = 6 ORDER BY 2 TO SELECT * FROM tbl1 WHERE col1 = 4 AND col2 = 6 ORDER BY 2;
注意
在使用 target_stmt 时,严格要求 stmt 与 target_stmt 在去掉 Hint 后完全匹配。
如下示例中,优化器可能默认会选择走 idx_c2 索引。索引上只有索引列 c2 和主键列 c1(索引上的主键列在索引中是隐藏列,仅用于索引回表),因为结果中还需要返回 c3 列的值,所以需要索引回表查出 c3 列。
索引回表一行的代价远远大于全表扫描一行的代价(大概是十倍左右的代价)。如果用户已知 c2 列的过滤性很差,所以把该 SQL 改为强制走全表扫描,性能反倒会更优。此时可以通过创建 Outline 将该 SQL 绑定全表扫描的计划。
CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 INT, c3 INT, INDEX idx_c2(c2));
INSERT INTO t1 VALUES(1, 1, 1), (2, 1, 2), (3, 1, 3);
EXPLAIN SELECT * FROM t1 WHERE c2 = 1;
+-----------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------+
| ====================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------ |
| |0 |TABLE RANGE SCAN|t1(idx_c2)|1 |7 | |
| ====================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2], [t1.c3]), filter(nil), rowset=16 |
| access([t1.c1], [t1.c2], [t1.c3]), partitions(p0) |
| is_index_back=true, is_global_index=false, |
| range_key([t1.c2], [t1.c1]), range(1,MIN ; 1,MAX), |
| range_cond([t1.c2 = 1]) |
+-----------------------------------------------------------------+根据如下 SQL 语句创建 Outline:
CREATE OR REPLACE OUTLINE otl_t1_full ON SELECT /*+ full(t1) */ * FROM t1 WHERE c2 = 1;为了确认某一条 SQL 在执行时的真实计划,不应该直接执行 explain 语句,而是要通过查询上述的两个计划监控视图 GV$OB_PLAN_CACHE_PLAN_STAT 和 GV$OB_PLAN_CACHE_PLAN_EXPLAIN。详见下文 确定 Outline 创建生效 部分。
使用 SQL_ID 创建 Outline
使用 SQL_ID 创建 Outline 的语法如下:
CREATE OUTLINE outline_name ON sql_id USING HINT hint_text;SQL_ID 为需要绑定的 SQL 对应的 SQL_ID,可以查询 GV$OB_PLAN_CACHE_PLAN_STAT 获取。
select
TENANT_ID,
SVR_IP,
SVR_PORT,
PLAN_ID,
LAST_ACTIVE_TIME,
QUERY_SQL,
SQL_ID
from
oceanbase.GV$OB_PLAN_CACHE_PLAN_STAT
where
QUERY_SQL = 'SELECT * FROM t1 WHERE c2 = 1';输出如下:
+-----------+--------------+----------+---------+----------------------------+-------------------------------+----------------------------------+
| TENANT_ID | SVR_IP | SVR_PORT | PLAN_ID | LAST_ACTIVE_TIME | QUERY_SQL | SQL_ID |
+-----------+--------------+----------+---------+----------------------------+-------------------------------+----------------------------------+
| 1002 | 10.10.10.1 | 22602 | 49820 | 2024-03-13 18:49:17.375906 | SELECT * FROM t1 WHERE c2 = 1 | ED570339F2C856BA96008A29EDF04C74 |
+-----------+--------------+----------+---------+----------------------------+-------------------------------+----------------------------------+使用 SQL_ID 绑定 Outline,如下例所示:
DROP OUTLINE otl_t1_full;
CREATE OUTLINE otl_t1_idx_c2 ON "ED570339F2C856BA96008A29EDF04C74" USING HINT /*+ INDEX(t1 idx_c2)*/ ;
注意
Hint 格式为 /*+ xxx*/。
使用 SQL_TEXT 方式创建的 Outline 会覆盖 SQL_ID 方式创建的 Outline。SQL_TEXT 方式创建的优先级更高。
如果 SQL_ID 对应的 SQL 语句已经有 Hint,则创建 Outline 指定的 Hint 会覆盖原始语句中所有 Hint。
Outline Data 是优化器为了完全复现某一计划而生成的一组 Hint 信息,以 BEGIN_OUTLINE_DATA 开始,并以 END_OUTLINE_DATA 结束。Outline Data 信息可以通过 EXPLAIN outline 命令获得,如下例所示:
EXPLAIN outline SELECT/*+ index(t1 idx_c2)*/ * FROM t1 WHERE c2 = 1;输出如下:
-----------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------+
| ====================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------ |
| |0 |TABLE RANGE SCAN|t1(idx_c2)|3 |12 | |
| ====================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2], [t1.c3]), filter(nil), rowset=16 |
| access([t1.c1], [t1.c2], [t1.c3]), partitions(p0) |
| is_index_back=true, is_global_index=false, |
| range_key([t1.c2], [t1.c1]), range(1,MIN ; 1,MAX), |
| range_cond([t1.c2 = 1]) |
| Outline Data: |
| ------------------------------------- |
| /*+ |
| BEGIN_OUTLINE_DATA |
| INDEX(@"SEL$1" "test"."t1"@"SEL$1" "idx_c2") |
| OPTIMIZER_FEATURES_ENABLE('4.0.0.0') |
| END_OUTLINE_DATA |
| */ |
+-----------------------------------------------------------------+其中 Outline Data 信息如下所示:
Outline Data:
-------------------------------------
/*+
BEGIN_OUTLINE_DATA
INDEX(@"SEL$1" "test"."t1"@"SEL$1" "idx_c2")
OPTIMIZER_FEATURES_ENABLE('4.0.0.0')
END_OUTLINE_DATA
*/Outline Data 也属于 Hint,因此可以用在计划绑定的过程中,如下例所示:
DROP OUTLINE otl_t1_idx_c2;
CREATE OUTLINE otl_t1_idx_c2
ON "ED570339F2C856BA96008A29EDF04C74" USING HINT
/*+
BEGIN_OUTLINE_DATA
INDEX(@"SEL$1" "test"."t1"@"SEL$1" "idx_c2")
OPTIMIZER_FEATURES_ENABLE('4.0.0.0')
END_OUTLINE_DATA
*/;确定 Outline 创建生效
确定创建的 Outline 是否成功且符合预期,需要进行如下三步的验证:
确定 Outline 创建成功。通过查看 DBA_OB_OUTLINES 视图,确认是否成功创建对应名称的 Outline。
SELECT * FROM oceanbase.DBA_OB_OUTLINES WHERE OUTLINE_NAME = 'otl_t1_full'\G输出如下:
*************************** 1. row ***************************
CREATE_TIME: 2024-03-13 18:38:18.807692
MODIFY_TIME: 2024-03-13 18:39:57.210761
TENANT_ID: 1002
DATABASE_ID: 500001
OUTLINE_ID: 500133
DATABASE_NAME: test
OUTLINE_NAME: otl_t1_full
VISIBLE_SIGNATURE: SELECT * FROM t1 WHERE c2 = ?
SQL_TEXT: SELECT/*+ full(t1) */ * FROM t1 WHERE c2 = 1
OUTLINE_TARGET:
OUTLINE_SQL: SELECT /*+BEGIN_OUTLINE_DATA FULL(@"SEL$1" "test"."t1"@"SEL$1") OPTIMIZER_FEATURES_ENABLE('4.0.0.0') END_OUTLINE_DATA*/* FROM t1 WHERE c2 = 1
SQL_ID:
OUTLINE_CONTENT: /*+BEGIN_OUTLINE_DATA FULL(@"SEL$1" "test"."t1"@"SEL$1") OPTIMIZER_FEATURES_ENABLE('4.0.0.0') END_OUTLINE_DATA*/
确定新的 SQL 是否通过绑定的 Outline 生成了新执行计划。当绑定 Outline 的 SQL 执行新的查询后,查询 GV$OB_PLAN_CACHE_PLAN_STAT 表中该 SQL 对应的计划信息中的 outline_id。如果 outline_id 与在 DBA_OB_OUTLINES 中查到的 outline_id 相同,则表示是按绑定的 Outline 生成的执行计划,否则不是。
SELECT SQL_ID, PLAN_ID, STATEMENT, OUTLINE_ID, OUTLINE_DATA
FROM oceanbase.GV$OB_PLAN_CACHE_PLAN_STAT
WHERE STATEMENT LIKE '%SELECT * FROM t1 WHERE c2 =%'\G输出如下:
*************************** 1. row ***************************
SQL_ID: ED570339F2C856BA96008A29EDF04C74
PLAN_ID: 49820
STATEMENT: SELECT * FROM t1 WHERE c2 = ?
OUTLINE_ID: 500133
OUTLINE_DATA: /*+BEGIN_OUTLINE_DATA FULL(@"SEL$1" "test"."t1"@"SEL$1") OPTIMIZER_FEATURES_ENABLE('4.0.0.0') END_OUTLINE_DATA*/
确定生成的执行计划是否符合预期。确定是通过绑定的 Outline 生成的计划后,需要确定生成的计划是否符合预期,可以通过查询 GV$OB_PLAN_CACHE_PLAN_EXPLAIN 表查看 plan_cache 中缓存的执行计划形状,具体查看方式可参见官网《OceanBase 数据库》文档 参考指南/性能调优/SQL 调优指南/SQL 执行计划/实时执行计划展示 。
通过 GV$OB_PLAN_CACHE_PLAN_STAT 查询上述 SQL 对应的 TENANT_ID、SVR_IP、SVR_PORT、PLAN_ID 字段。 select TENANT_ID, SVR_IP, SVR_PORT, PLAN_ID, LAST_ACTIVE_TIME, QUERY_SQL from oceanbase.GV$OB_PLAN_CACHE_PLAN_STAT where QUERY_SQL = 'SELECT * FROM t1 WHERE c2 = 1'; 输出如下: +-----------+--------------+----------+---------+----------------------------+-------------------------------+ | TENANT_ID | SVR_IP | SVR_PORT | PLAN_ID | LAST_ACTIVE_TIME | QUERY_SQL | +-----------+--------------+----------+---------+----------------------------+-------------------------------+ | 1002 | 10.10.10.1 | 22602 | 49820 | 2024-03-13 18:49:17.375906 | SELECT * FROM t1 WHERE c2 = 1 | +-----------+--------------+----------+---------+----------------------------+-------------------------------+
根据输出,通过 oceanbase.GV$OB_PLAN_CACHE_PLAN_EXPLAIN 来看 SQL 对应的真实计划,GV$OB_PLAN_CACHE_PLAN_EXPLAIN 视图各字段含义详见官网《OceanBase 数据库》文档 参考指南/系统视图/MySQL 租户系统视图/性能视图/GV$OB_PLAN_CACHE_PLAN_EXPLAIN 。 SELECT * FROM oceanbase.GV$OB_PLAN_CACHE_PLAN_EXPLAIN WHERE tenant_id = 1002 AND SVR_IP = '10.10.10.1' AND SVR_PORT = 22602 AND PLAN_ID = 49820; 输出如下: +-----------+--------------+----------+---------+------------+--------------+----------------+------+------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | TENANT_ID | SVR_IP | SVR_PORT | PLAN_ID | PLAN_DEPTH | PLAN_LINE_ID | OPERATOR | NAME | ROWS | COST | PROPERTY | +-----------+--------------+----------+---------+------------+--------------+----------------+------+------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | 1002 | 10.10.10.1 | 22602 | 49820 | 0 | 0 | PHY_TABLE_SCAN | t1 | 1 | 3 | table_rows:3, physical_range_rows:3, logical_range_rows:3, index_back_rows:0, output_rows:1, avaiable_index_name[idx_c2,t1], pruned_index_name[idx_c2], estimation info[table_id:500131, (table_type:0, version:-1--1--1, logical_rc:3, physical_rc:3)] | +-----------+--------------+----------+---------+------------+--------------+----------------+------+------+------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 您也可以通过 DBMS_XPLAN.DISPLAY_CURSOR 来看 SQL 对应的真实计划,展示出来的信息比 oceanbase.GV$OB_PLAN_CACHE_PLAN_EXPLAIN 更像 explain 展示出来的信息,详见官网《OceanBase 数据库》文档 参考指南/SQL 参考/PL 参考/PL 参考(MySQL 模式)/PL 系统包/DBMS_XPLAN/DISPLAY_CURSOR 。 SELECT DBMS_XPLAN.DISPLAY_CURSOR( 49820, 'typical', '10.10.10.1', 22602, 1002 ) FROM DUAL; 输出如下: ================================================================================================ |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)|REAL.ROWS|REAL.TIME(us)|IO TIME(us)|CPU TIME(us)| ------------------------------------------------------------------------------------------------ |0 |TABLE FULL SCAN|t1 |1 |4 |3 |0 |0 |0 | ================================================================================================ Outputs & filters: ------------------------------------- 0 - output([t1.c1], [t1.c2], [t1.c3]), filter([t1.c2 = :0]), rowset=16 access([t1.c1], [t1.c2], [t1.c3]), partitions(p0) is_index_back=false, is_global_index=false, filter_before_indexback[false], range_key([t1.c1]), range(MIN ; MAX)always true
删除 Outline
删除 Outline 后,对应 SQL 将不再依据所绑定的 Outline 重新生成执行计划。删除 Outline 的语法如下:
DROP OUTLINE outline_name;计划绑定与执行计划缓存关系
使用 SQL_TEXT 创建 Outline 后,SQL 请求生成新计划查找 Outline 使用的 Key 与计划缓存使用的 Key 是相同的,即均是 SQL 参数化后的文本串。
当创建和删除 Outline 后,对应 SQL 有新的请求时,会触发执行计划缓存中对应执行计划失效,更新为根据绑定的 Outline 所生成的执行计划。
计划绑定与限流规则的关系
从 OceanBase 数据库 4.2.2 版本开始,数据库的 CREATE OUTLINE 和 ALTER OUTLINE 命令扩展了功能。除了原有的绑定特定查询的执行计划外,还允许用户为查询设置最大并发执行次数的限制。限流功能能够帮助大家更有效地管理数据库负载,防止因高并发查询而导致的性能问题。
例如:
使用 CREATE OUTLINE 创建了一个 OUTLINE,其中包含了 USE_NL(tbl2) 提示,这告诉优化器对于表 tbl2 使用 nest loop join,同时 MAX_CONCURRENT(1) 这个 Hint 在下面这个示例中表示同一时刻,只允许一个线程执行查询:
CREATE OUTLINE otl2 ON SELECT /*+ USE_NL(tbl2) MAX_CONCURRENT(1) */ * FROM t WHERE c1 = ?;
同样地,使用 ALTER OUTLINE 修改现有 OUTLINE,同样可以达到上述效果。
ALTER OUTLINE otl2 ON SELECT /*+ USE_NL(tbl2) MAX_CONCURRENT(1) */ * FROM t WHERE c1 = ?;